Global Manufacturer Giant — Enterprise Exception Handling & Self-Healing Framework
Summary
Implemented an enterprise exception handling & self-healing framework that normalized faults across SOA composites, OSB services, and ODI jobs, converted them into a single error taxonomy, and auto-raised incidents with context. The system throttled duplicates, shut down storming services safely, and exposed one-click reprocessing/bring-up, reducing MTTR and preventing cascades.
Problem
- Scattered handling & noisy logs: Inconsistent patterns across Java/SOA/OSB/ODI meant errors were handled ad-hoc; critical signals were buried.
- High MTTR & operator fatigue: Repeated faults created storm conditions; tickets were raised late or without context.
- No safe-stop controls: Faulty endpoints caused retries, dead-letter growth, and upstream saturation; bring-up steps were manual and error-prone.
Solution Mechanics
Primary pattern: Rules/validation (central taxonomy + fault policies + duplicate detection).
Secondary pattern: API-led orchestration (controlled lifecycle, ticketing, and reprocessing services).
-
Normalization & Capture
- Standardized fault policies in composites; consistent catch/catch-all usage with canonical AIA fault message.
- OSB error handlers published fault details; ODI logged to a custom table and invoked the framework.
- All paths converged on an AIA Error Topic (JMS) for one ingress.
-
Error Listener & Classification
- Error Listener service consumed the AIA topic and persisted records to ERROR_NOTIFICATION_INFO.
- Duplicate detector (time-window, service + business ID) classified new vs duplicate; throttled notifications.
-
Automated Response & Ticketing
- New: routed to IMS_ERRORFALLOUT_Q → Fallout Consumer assembled Remedy payload (from REMEDY_GROUP_DETAILS) and created an incident; emailed owners.
- Duplicate: fetched policy from ERROR_REFERENCE/SERVICE_REFERENCE; when shutdown required, invoked Lifecycle Service to disable OSB proxies or stop SOA services; status updated via ErrorHandlingDBService.
-
Controlled Bring-up & Reprocessing
- Heartbeat Service (input: target name, optional START/STOP) invoked Error Reprocessing Service to walk TARGET_SERVICE_MAPPING and start/enable or stop/disable dependent services in order.
- Message resubmission utilities and DLQ/replay scripts restored transactions once dependencies recovered.
-
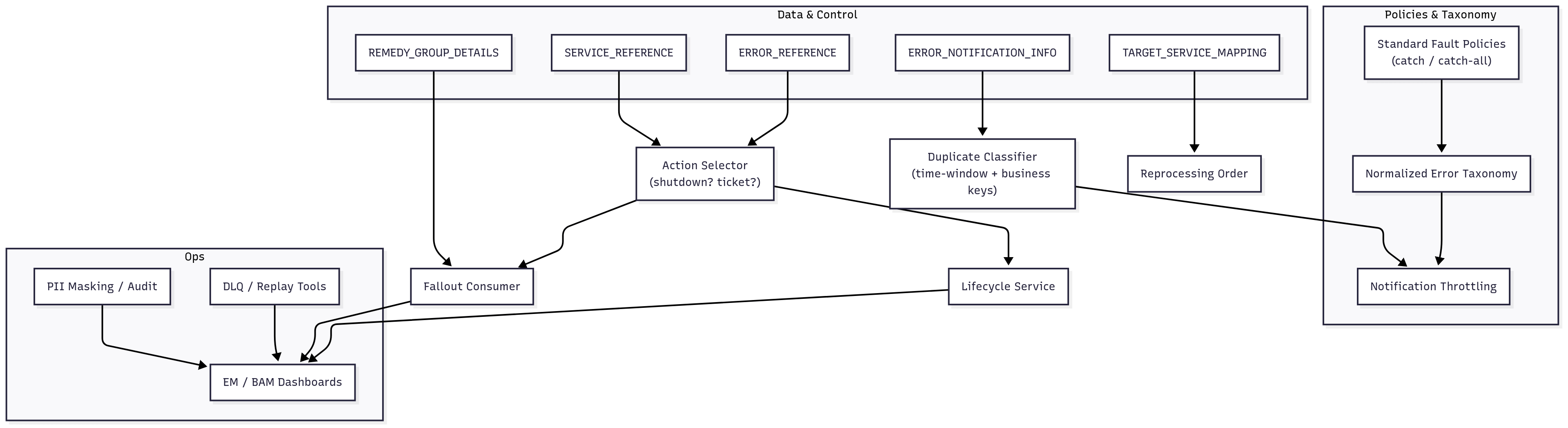
Data & Governance
- Canonical tables: ERROR_NOTIFICATION_INFO, ERROR_REFERENCE, SERVICE_REFERENCE, TARGET_SERVICE_MAPPING, REMEDY_GROUP_DETAILS.
- Notification throttling; audit trails (who/what/when), policy versioning, and role-based visibility.
- Enterprise Manager/BAM for drill-downs; masked PII in logs.
Diagram 1 - Context Diagram — Centralized error intake, classification, ticketing, and lifecycle control
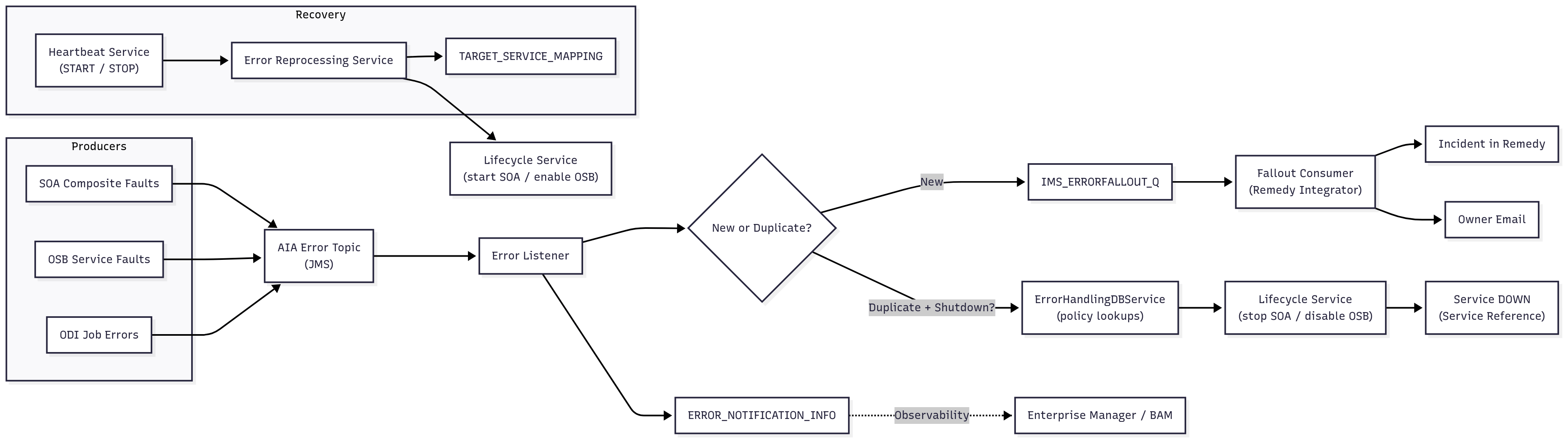
Diagram 2 - Sequence — Fault → normalize → classify (new/duplicate) → ticket or controlled shutdown → heartbeat bring-up
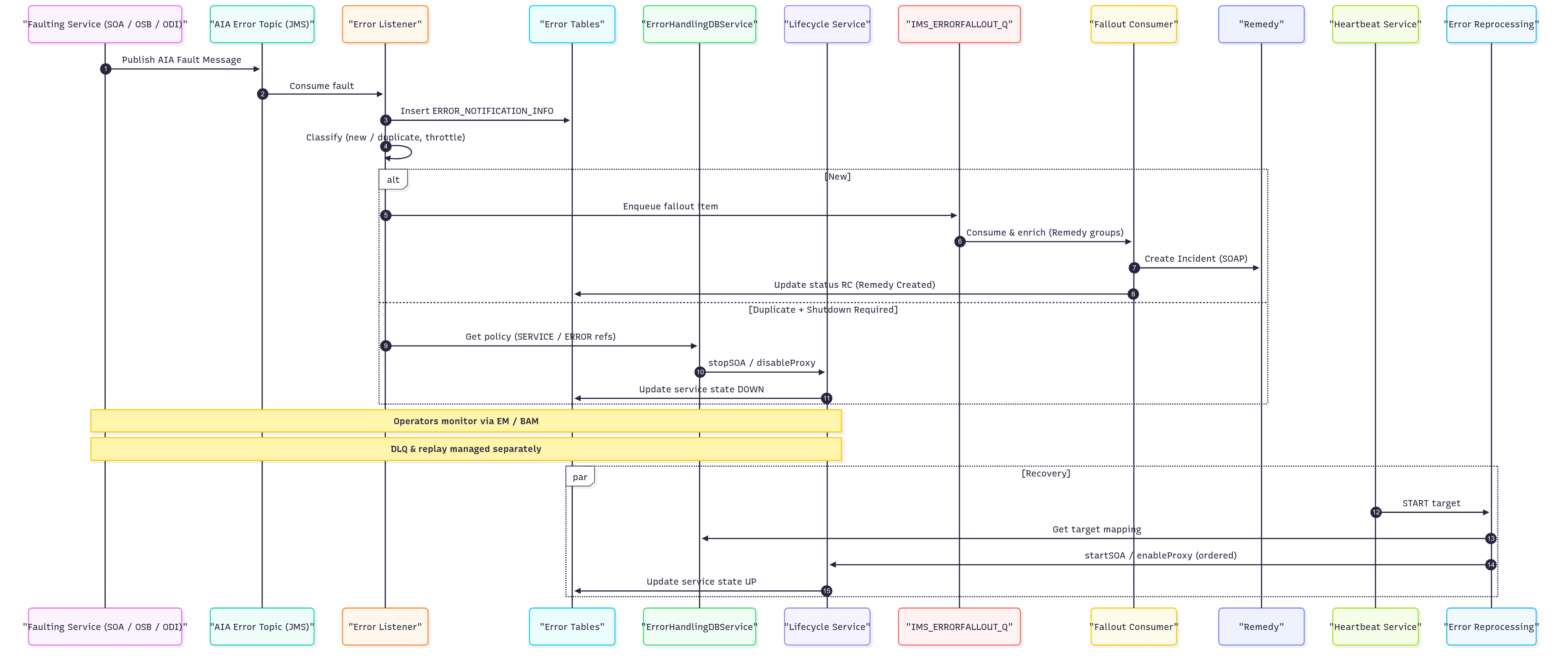
Diagram 3 - Operations — Throttling, DLQ/replay, tables & policy versioning
Process Flow
- SOA/OSB/ODI emits an error → normalized into AIA fault message and published to the AIA Error Topic (JMS).
- Error Listener persists to ERROR_NOTIFICATION_INFO and classifies by duplicate window + business identifiers.
- If new → post to IMS_ERRORFALLOUT_Q; Fallout Consumer enriches from REMEDY_GROUP_DETAILS and creates Remedy incident; email sent to the owning group.
- If duplicate and shutdown required → fetch policy from ERROR_REFERENCE/SERVICE_REFERENCE → call Lifecycle Service to disable OSB / stop SOA; mark service DOWN.
- Operators view details in Enterprise Manager/BAM; DLQ items are parked and tracked.
- On recovery, Heartbeat Service (START) triggers Error Reprocessing Service to enable/start impacted services using TARGET_SERVICE_MAPPING order.
- Replay/resubmit messages; update ERROR_NOTIFICATION_INFO/SERVICE_REFERENCE; close incident with context.
- Unknown patterns flow to an “unclassified” bucket for taxonomy update and policy tuning.
Outcomes
- Lower MTTR via auto-ticketing with context and consistent diagnostics.
- Storm prevention by safely halting repeating offenders and coordinated re-start.
- Operational clarity with one error taxonomy, throttled notifications, and drill-downs.
Strategic Business Impact
- MTTR –30–60% (Modeled) — assumes baseline incident volumes and duplicate suppression window; measured reductions on selected interfaces extrapolated.
- Ticket quality uplift (Proxy) — higher first-time-fix from enriched incidents (service, instance, business identifiers).
- Outage containment (Proxy) — fewer cross-system cascades due to controlled shutdown and ordered bring-up.
Role & Scope
Owned framework architecture and rollout: fault policy standards, taxonomy, Error Listener, ErrorHandlingDBService, Lifecycle/Heartbeat/Reprocessing services, Fallout/Remedy integration, DLQ/replay tooling, tables and audits, and OEM/BAM dashboards.
Key Decisions & Trade-offs
- Centralized taxonomy + topic intake vs per-app handling → uniform ops view; requires migration of legacy handlers.
- Duplicate window & throttling curbs alert fatigue; risk of masking rare bursts → mitigated by role-based overrides.
- Controlled shutdown contains blast radius; demands ordered bring-up and dependency mapping.
- Ticket automation (Remedy) accelerates response; tight coupling to ticket schema needs version governance.
- Strict PII masking safeguards data; limits some ad-hoc queries → solved with redaction-aware dashboards.
Risks & Mitigations
- False positives in duplicate detection → tune window + add business keys; manual override path.
- Shutdown loops if root cause persists → backoff strategy; cap attempts; require operator ack beyond N cycles.
- Ticket storms from upstream retries → throttling + roll-up incidents per service/tenant.
- DLQ growth → aging alerts, replay windows, and auto-archive rules.
- Policy drift across teams → versioned policies, pre-prod validation pack, and mandatory catch/catch-all linting.
Suggested Metrics (run-time SLOs)
- Error-to-ticket time p95 (ingest → incident created).
- Duplicate suppression rate and notification throttle hit rate.
- Automatic shutdown mean time (first duplicate → action) and bring-up success rate.
- DLQ depth & replay age per interface.
- Unknown-to-classified ratio over rolling 30 days.
- Policy compliance (% services with standardized fault policy & catch blocks).
Closing principle
Treat errors as data, not noise—normalize, act safely, and learn on every repeat.